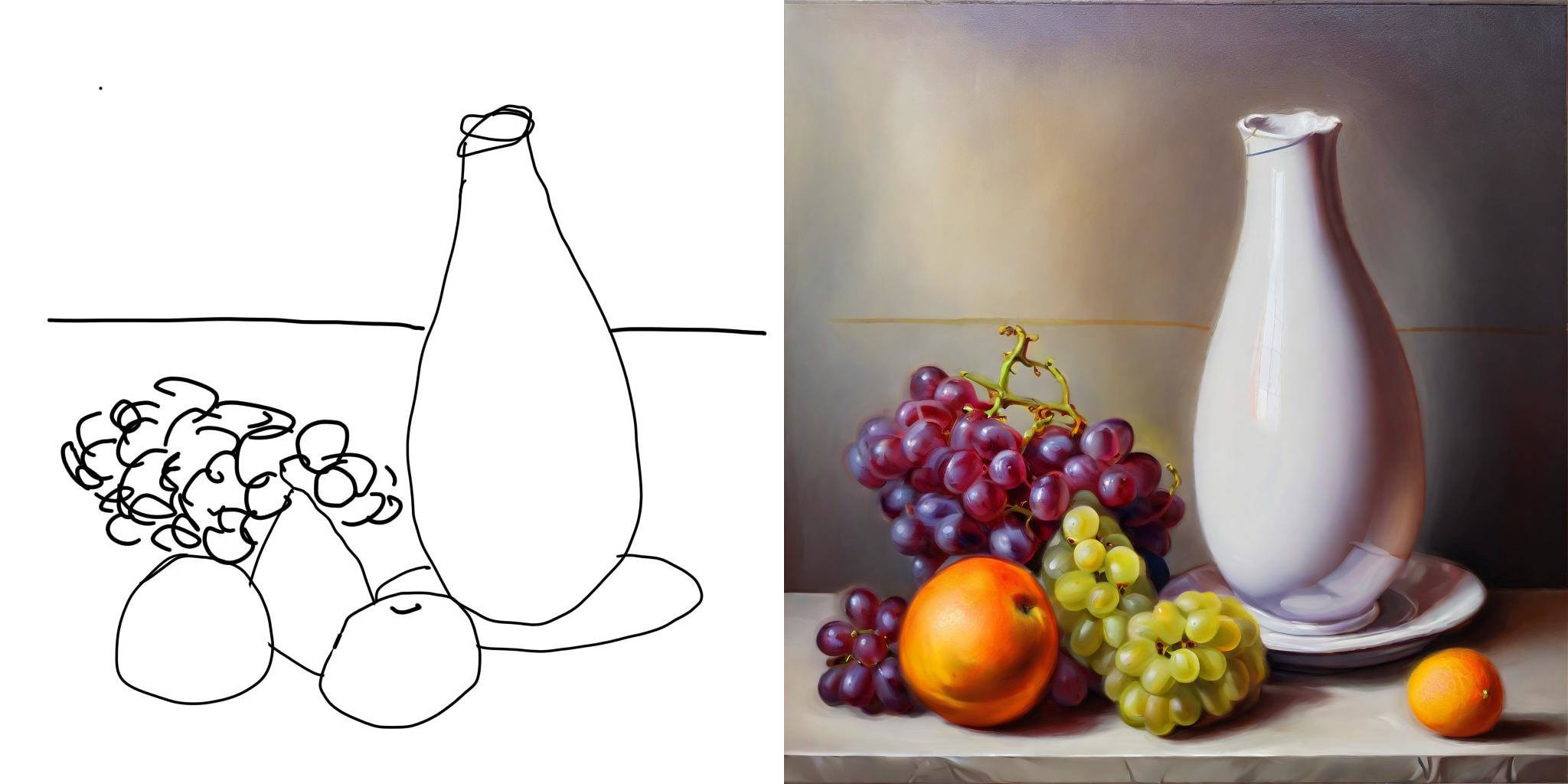
Добавил новую функцию для telegram-бота @pixelmuse_bot. Теперь на вход ему можно отправить кривой рисунок с командой в описании /imagine2 текст запроса и на выходе получить что-то осмысленное и даже красивое.
Как это работает под капотом. Никакой магии, для управления нейросетью используем controlnet. Controlnet заставляет нейросеть использовать информацию о границах объектов как опору для создания нового изображения.
После получения изображения от пользователя обрабатываем его с помощью cv2.Canny для определения краев. Тут пришлось поэксперементировать с параметрами чтобы края определялись в том числе на фотографиях, где переходы, например на лице, могут быть плавными, а потеря этих границ даёт модели слишком много свободы для творчества.
Для теста нарисовал такой рисунок:

Загружаем исходное изображенние с помощью PIL, кропаем и ресайзим до нужного размера:
image = Image.open(image_path)
image = crop(image)
image = image.resize((width, height))
Используем cv2.Canny для создания маски с краями объектов:
image = np.array(image)
image = cv2.Canny(image, 55, 70) # эти параметры надо продобрать под ваши изображения
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
Получаем что-то такое:

В этом проекте я загружаю одну SDXL модель и переиспользую ее для разных задач и комбинаций с LoRa. Загрузка базовой модели происходит из файла safetensors примерно так:
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix",
torch_dtype=torch.float16)
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-canny-sdxl-1.0",
torch_dtype=torch.float16)
pipe = StableDiffusionXLPipeline.from_single_file(
model_path,
custom_pipeline="lpw_stable_diffusion",
max_embeddings_multiples=3,
vae=vae,
use_safetensors=True,
variant="fp16",
torch_dtype=torch.float16)
pipe.enable_vae_tiling()
pipe.enable_xformers_memory_efficient_attention()
pipe.scheduler = DPMSolverMultistepScheduler.from_config(
pipe.scheduler.config,
use_karras_sigmas=True)
Затем инициализируем StableDiffusionXLControlNetPipeline с помощью уже загруженной модели и controlnet:
pipe_ctrlnet = StableDiffusionXLControlNetPipeline(
**pipe.components,
controlnet=controlnet).to('cuda')
И генерим изображение:
images = pipe_ctrlnet(
prompt=prompt,
negative_prompt=negative_prompt,
image=canny_image,
num_inference_steps=20,
controlnet_conditioning_scale=0.5,
guidance_scale=guidance_scale).images
Результат на выходе:
